도입: 게임의 왕, 3D V-Cache
AMD의 3D V-Cache 기술은 처음 출시 이후 게이머들 사이에서 “게임 성능의 왕"으로 불렸다. CPU 다이 위에 L3 캐시를 수직으로 적층하여 기존 384MB에서 최대 1,152MB까지 확장한 이 기술은, 게임 중심의 랜덤 데이터 접근 패턴에 정확히 최적화되어 있다.
Ryzen 9 9950X3D는 동일한 9950X 대비 Baldur’s Gate 3에서 54% FPS 향상, Starfield에서 37% 향상을 달성하며, 전작 7950X3D 대비 15% 게임 성능 향상을 제공한다. 이는 단순히 “조금 빠른” 수준이 아니라 세대 간 점프에 가까운 개선이다.
게임 커뮤니티에서는 이렇게 평가한다: “3D V-Cache는 순수 멀티스레드 성능으로는 표준 모델을 따라잡지 못하지만, 게임이라는 특정 영역에서만큼은 거의 모든 제약을 제거하는 기술이다.” 실제로 저가 CPU인 7800X3D가 고가의 고클럭 Intel Core i9-13900K를 게임에서 압도하는 현상은 캐시의 중요성을 명확히 보여준다.
게임 벤치마크 상세 분석
캐시 민감도에 따른 성능 차이
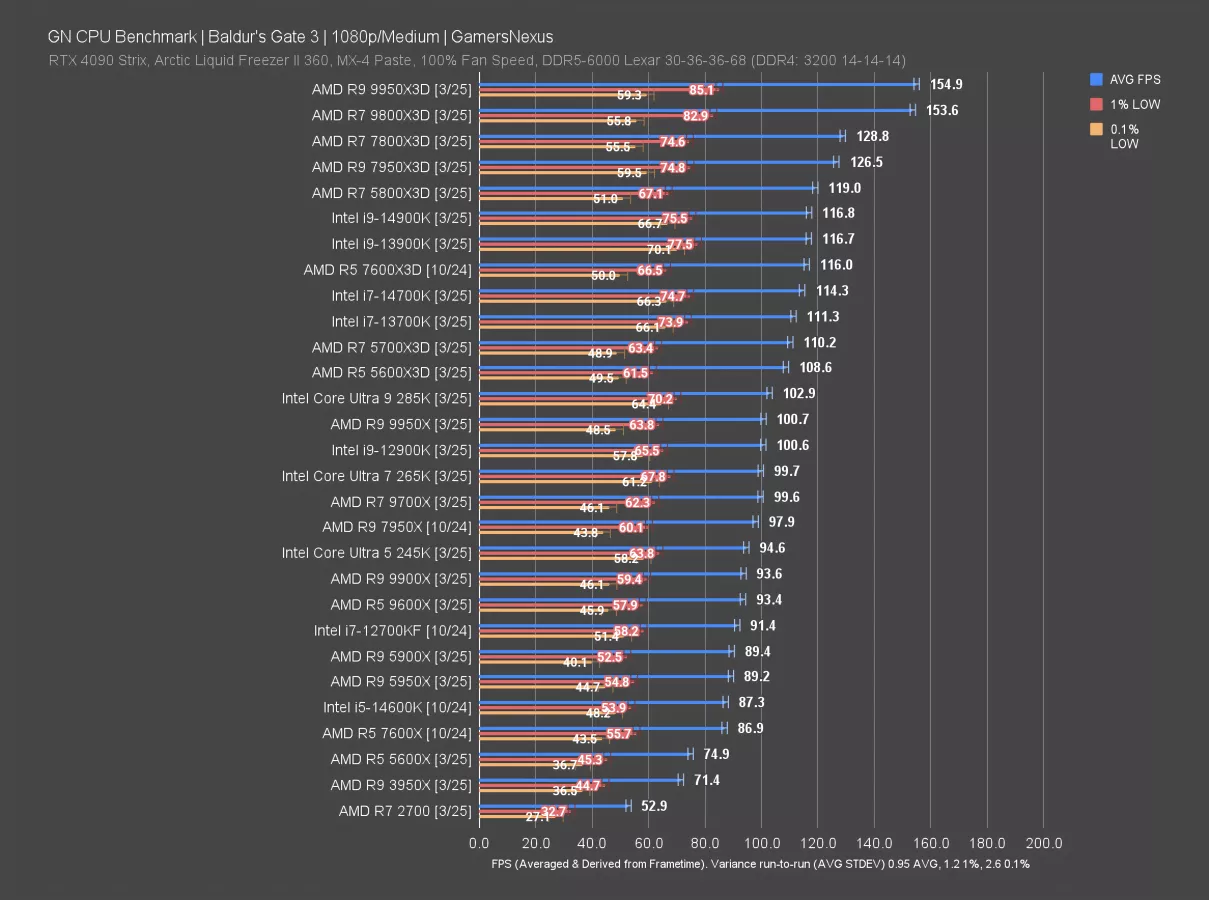
게임별로 3D V-Cache의 효과는 극명하게 갈린다는 점이 흥미롭다.
캐시에 매우 민감한 게임:
- Baldur’s Gate 3: 9950X3D 155 FPS vs 9950X 101 FPS (54% 향상) - 턴 기반 RPG로 광대한 맵 데이터와 엔티티 상태가 L3에 들어오면 성능이 폭발한다.
- Starfield: 9950X3D 171 FPS vs 9950X 124 FPS (37% 향상) - 광활한 우주 시뮬레이션에서 높은 CPU 부하를 보인다.
- Final Fantasy XIV Dawntrail: 9950X3D 373 FPS vs 9950X 323 FPS (16% 향상) - MMORPG의 동적 렌더링에 효과적이다.
GPU 병목 워크로드:
- Cyberpunk 2077: 9950X3D 219 FPS vs 9950X 219 FPS (거의 동일) - 고해상도 레이트레이싱에서 GPU가 병목이 되어, CPU 성능 차이가 무시된다.
최소 FPS의 극적 개선
이전 세대의 더 세부적인 분석을 보면, 게임 ‘쾌적성’ 측면에서 3D V-Cache의 진정한 가치가 드러난다.
레드 데드 리뎐션 2 (FHD 최고 옵션):
- 평균 FPS: 7950X 140.9 vs 7950X3D 141.57 (거의 같음)
- 최소 FPS: 7950X 86 vs 7950X3D 106.7 (24% 향상) ← 게임 체감 부드러움이 크게 개선된다.
사이버펑크 2077 (FHD 울트라):
- 평균 FPS: 7950X 209.6 vs 7950X3D 214 (2% 미미)
- 최소 FPS: 7950X 56.7 vs 7950X3D 73.8 (30% 향상) ← 끊김 현상이 완화된다.
이 패턴은 중요한 통찰을 제시한다: 3D V-Cache는 "최대 성능"보다 "최소 성능 안정성"을 보장하는 기술이다. 평균 FPS가 60대인 상황에서 최소 FPS가 30까지 떨어지면 게임은 “끊긴다"고 느껴진다. 3D V-Cache는 이러한 프레임 드롭의 골짜기를 높여, 게임 경험을 근본적으로 개선한다.
게임 공급사도 이를 인정한다: “3D V-Cache는 게임 성능을 거의 완벽하게 동일화시키는 기술이다. 단일 스레드, 듀얼 코어 CPU와 고클럭 멀티코어 CPU 간 게임 FPS 차이를 대부분 없애버린다.”
터닝 포인트: “게임뿐만 아니라” 서버와 HPC로의 확장
EPYC 서버 CPU의 등장과 패러다임 변화
AMD가 서버 플랫폼인 EPYC 9000 시리즈(Genoa)에 3D V-Cache를 탑재한 것은 2023년의 중요한 분기점이다. 단순히 “고급 기능"이 아니라 데이터센터 성능의 새로운 기준을 정의한 것이다.
일반적인 인식은 다음과 같다:
- 게임 CPU 3D V-Cache (Ryzen): 게이머 전용 성능 최적화
- 서버 CPU 3D V-Cache (EPYC): 완전히 다른 목적의 기술
하지만 실제 데이터는 이를 깨뜨렸다.
Redis 인메모리 데이터베이스: 2배 이상의 처리량
구체적인 벤치마크 수치
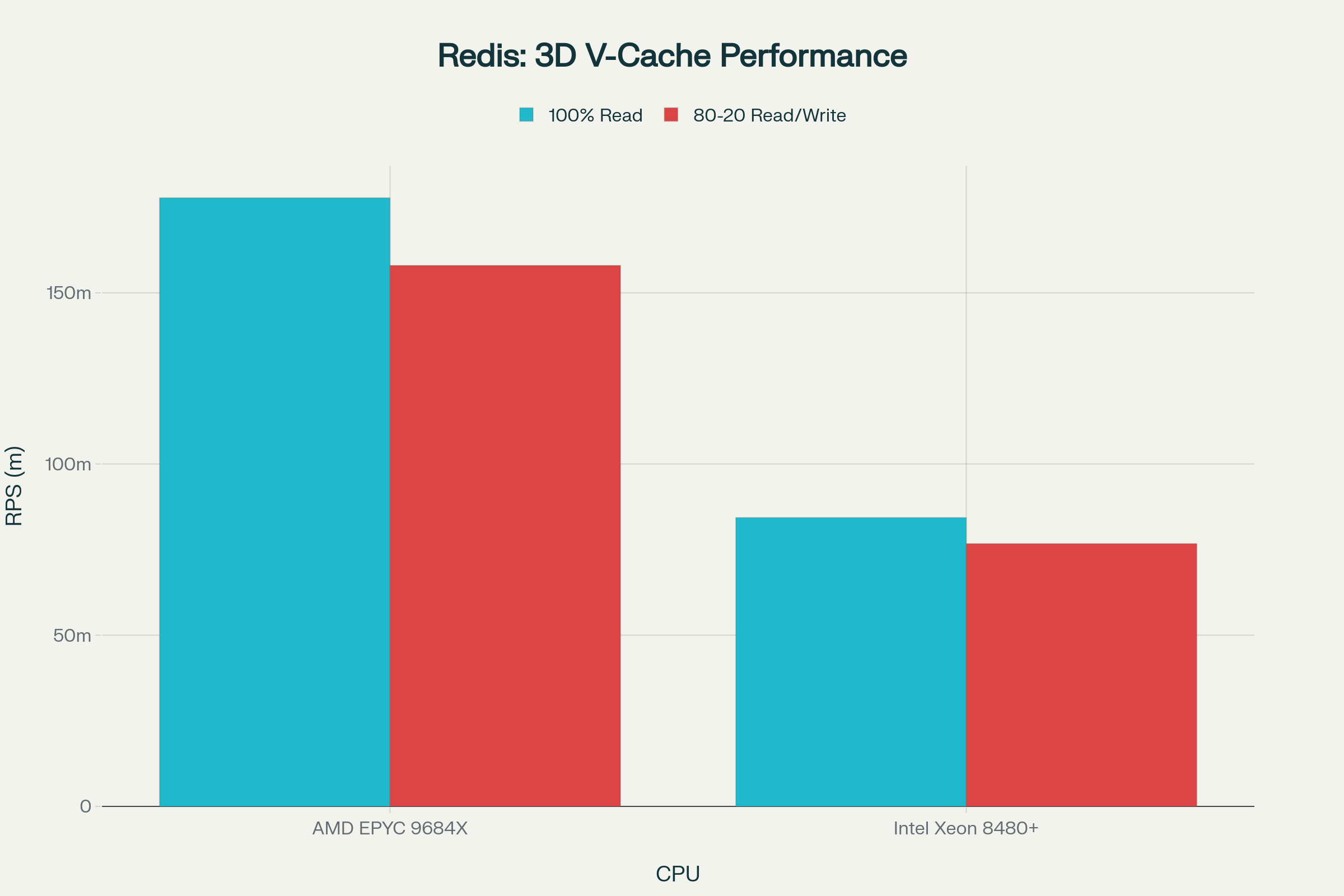
Principled Technologies의 벤치마크(EPYC 9684X vs Intel Xeon 8480+)는 인메모리 워크로드에서 3D V-Cache의 영향력을 극명하게 보여준다.
100% Read 워크로드 (순수 조회 성능):
- AMD EPYC 9684X (3D V-Cache): 177.7M RPS (Requests Per Second)
- Intel Xeon 8480+: 84.4M RPS
- 성능 향상: 110.7% (2배 이상)
80-20 Read/Write 혼합:
- AMD EPYC 9684X: 158.0M RPS
- Intel Xeon 8480+: 76.8 RPS
- 성능 향상: 105.8%
전력 효율성까지 고려:
- Performance/Watt: 9684X 175,894 vs 8480+ 84,162
- 효율성 109% 향상 (동일 전력으로 2배 처리)
왜 Redis에서만큼은 게임과 같은 원리가 작동하는가?
이 결과는 “게임과 데이터베이스는 완전히 다르다"는 통념을 깨뜨린다. 그 이유는 캐시 접근 패턴의 공통점에 있다:
- 랜덤 데이터 접근: 게임의 엔티티 검색, Redis의 키-값 조회 모두 예측 불가능한 위치의 데이터에 접근한다.
- 워킹셋이 L3 적합: 게임 맵 데이터와 게임 상태, Redis의 자주 사용되는 핫 데이터 모두 대형 L3에 들어온다.
- 메모리 지연이 처리량을 결정: 두 경우 모두 L3 히트율이 높을수록 DRAM 접근 횟수가 줄어 레이턴시가 개선된다.
게임과 Redis의 차이는 규모이다. 개인용 Ryzen 게이밍 CPU는 최대 96MB L3이지만, 서버용 EPYC 9684X는 1,152MB L3를 가진다. 따라서 이득이 게임의 20~54%에서 110% 이상으로 극대화되는 것이다.
Cloudflare 프로덕션 환경: 145% 처리량 향상의 실증
대규모 운영 환경에서의 검증
Cloudflare는 12세대 인프라에 EPYC 9684X(Genoa-X)를 도입하며, 자사의 실제 프로덕션 워크로드를 심층 분석한 결과를 공개했다.

“9684X가 표준 EPYC 9654 대비 145% 더 높은 처리량(throughput)과 63% 더 높은 전력 효율(efficiency)을 달성했다. 이는 동일한 물리 코어 수에서 순전히 L3 캐시 크기 차이로 인한 개선이다.”
이 145% 향상은 무엇을 의미하는가? 이는 다음과 같이 해석할 수 있다:
- 8개 표준 Genoa 노드를 9684X 4개 노드로 대체 가능하다.
- 데이터센터 랙 공간을 50% 절감한다.
- 냉각, 전력 공급 비용을 대폭 절감한다.
실제로 Cloudflare는 계산을 공개했다: “DDR5 대역폭이 이전 DDR4 대비 2배 증가했는데도, 여전히 L3 캐시 크기가 성능을 결정한다. 메모리 계층에서 캐시의 영향력은 불변의 법칙이다.”
OpenFOAM CFD 시뮬레이션: 2배 성능 도약
고성능 컴퓨팅의 시뮬레이션 워크로드
계산유체역학(Computational Fluid Dynamics)은 대규모 메시 데이터와 반복적 수치 해석을 수행하는 HPC 워크로드의 전형이다. 이 분야에서 3D V-Cache는 게임 수준을 훨씬 넘는 성능 향상을 가져온다.
OpenFOAM 벤치마크 결과:
- EPYC 9684X (Genoa-X, 1,152MB L3): 기준 성능 2.08배
- EPYC 9654 (표준 Genoa, 384MB L3): 1.0배 (기준)
- Intel Xeon 8462Y+ (HBM 기반): 0.53배
실제 의미는 다음과 같다:
- 9684X 1개 노드 = 표준 Genoa 2개 노드 성능
- 심지어 인텔의 HBM(고대역 메모리) 기반 고가형 CPU보다 3.9배 빠르다.
슈퍼리니어 스케일링의 출현
더욱 흥미로운 현상은 8노드 클러스터 테스트 결과이다. 이론적으로는 9684X 8개 노드 = 표준 Genoa 16개 노드여야 하지만:
- 실제 성능: 9684X 8노드 = Genoa 약 13노드 상당 (슈퍼리니어 스케일링 발생)
이는 왜 일어나는가? 이유는 워킹셋 적재 임계점에 있다:
- 표준 Genoa (384MB L3): 메시 데이터의 일부만 L3에 적재 → DRAM 접근 빈번 → 노드 간 통신 유도
- 9684X (1,152MB L3): 대부분의 메시 데이터와 중간 결과가 L3에 상주 → DRAM 접근 거의 없음 → 노드 간 통신 감소 → 스케일링 효율 상승
즉, 대형 L3는 단순히 “개별 노드를 빠르게” 하는 것이 아니라 클러스터 전체의 동기화 오버헤드를 줄여 슈퍼리니어 스케일링을 유도한다.
EDA 시뮬레이션: Synopsys VCS 검증 가속
반도체 설계 검증의 병목 해결
반도체 설계 산업에서 3D V-Cache의 역할은 특히 중요하다. Synopsys VCS(Verification Compiler System)는 수백만 라인의 설계를 기능적으로 검증하는 도구로, 메모리 접근 패턴이 극도로 불규칙하다.
성능 개선:
- EPYC 9384X (4세대, 3D V-Cache) vs EPYC 7573X (3세대, 표준)
- 약 1.28배 가속 (32코어 동일)
실제 영향:
- 설계 데이터베이스 쿼리 (메시 같은 불규칙 접근): L3 캐시에서 직결 가속
- 이벤트 시뮬레이션 (상태 전이 탐색): 갈라진 경로들이 L3에 들어오면 성능이 폭발한다.
- 형상 탐색 (SAT solver 등): NP-hard 문제의 부분해 캐싱 효율을 극대화한다.
3D V-Cache의 영역별 정결론
지금까지의 분석을 정리하면, 3D V-Cache의 가치는 게임에서 시작하여 서버, HPC, EDA까지 확산되고 있다.
극대 효과: 게임, 인메모리 DB, HPC 시뮬레이션
| 워크로드 | 성능 향상 | 이유 |
|---|---|---|
| 게임 (Baldur’s Gate 3 등) | 54% | 맵/엔티티 데이터가 L3에 적재, 캐시 히트율 70~90% |
| Redis 100% Read | 110% (2배) | 핫 데이터 대부분이 대형 L3에 상주 |
| CFD 시뮬레이션 | 2배 이상 | 메시 데이터 L3 적재 → 슈퍼리니어 스케일링 |
| Cloudflare 프로덕션 | 25~145% | 캐시 미스율 감소로 처리량 선형 증가 |
제한적 효과: 네트워크 병목, GPU 병목, 순차 스트리밍
| 워크로드 | 성능 향상 | 이유 |
|---|---|---|
| GPU 병목 게임 (Cyberpunk 2077) | 0% | GPU가 병목, CPU 개선이 무시된다. |
| 분산 시스템 (마이크로서비스) | 0~10% | 네트워크 지연이 CPU 캐시 이득을 압도한다. |
| 순차 스트리밍 (렌더, 컴파일) | 5~10% | AVX/벡터 성능과 클럭이 더 중요하다. |
| 메모리 스트리밍 (대형 행렬) | 0~5% | 메모리 대역폭이 병목, 캐시 히트율이 낮다. |
기술적 통찰: 왜 게임과 서버 워크로드가 같은 캐시에서 이득을 보는가?
캐시 친화성의 공통 특성
3D V-Cache가 게임과 서버 양쪽에서 효과적인 이유는 캐시 친화성 패턴에 있다:
-
높은 재사용율 (Reuse Distance):
- 게임: 엔티티 상태를 반복 조회 (프레임당 여러 번)
- Redis: 핫 키를 초당 수백만 번 조회
- 둘 다 같은 데이터를 짧은 시간 내 여러 번 접근한다.
-
큰 워킹셋 (Working Set):
- 게임: 한 번에 수백 MB의 씬 데이터가 필요하다.
- Redis: GB 단위의 데이터셋이 필요하다.
- 표준 CPU L3(64-96MB)로는 부족하며, 대형 L3(384-1152MB)가 필수적이다.
-
예측 불가능한 접근 (Random Access):
- 게임: 플레이어 행동에 따라 접근 패턴이 변화한다.
- Redis: 사용자 쿼리에 따라 키 접근 순서가 변화한다.
- 프리페칭(Prefetching)이 효과 없음 → L3 캐시 크기가 직결된다.
이는 CPU 아키텍처 관점에서 L1-L2 캐시의 한계를 명확히 보여준다. L1(32KB)과 L2(512KB)는 순차적 접근 최적화에 좋지만, 큰 비정형 데이터셋의 랜덤 접근에는 L3의 크기가 지배적이기 때문이다.
실전 응용: ROI 분석
언제 3D V-Cache를 채택할 것인가?
높은 ROI (즉시 도입 권장):
-
게이밍 PC/워크스테이션:
- 고주사율 게이밍 목표 → 9950X3D, 9800X3D를 권장한다.
- 1% 저점 프레임 안정성이 최우선 → 3D V-Cache가 필수적이다.
-
인메모리 데이터베이스 서비스:
- Redis, Memcached 중심 백엔드 → EPYC 9684X(Genoa-X)를 도입한다.
- 처리량 2배 = 서버 수 50% 감소 = 5년 TCO 30% 절감 효과를 가져온다.
-
HPC 클러스터:
- CFD, FEA, AI 훈련 등 시뮬레이션 → Genoa-X로 노드 수를 30% 감소시킨다.
- 전력, 냉각 비용 절감과 동시에 처리 시간을 50% 단축한다.
보통 ROI (신중하게 평가):
-
혼합 워크로드 데이터베이스 (OLTP + 분석):
- OLTP 부분에서 이득이 있으나, 분석 부분에서는 제한적이다.
- 실측 벤치마크가 필수적이다.
-
마이크로서비스 아키텍처:
- CPU 캐시 이득이 네트워크 지연에 가려질 가능성이 있다.
- 지연 시간(latency) 측정 후 결정한다.
낮은 ROI (도입 불권장):
-
GPU 중심 워크로드 (딥러닝 추론):
- GPU 병목이므로, CPU 개선이 무시된다.
- 표준 모델로도 충분하다.
-
스트리밍 데이터 처리 (로그 수집, 이벤트 처리):
- 순차 접근 위주이므로, 캐시 히트율이 낮다.
- 고클럭, 많은 코어가 더 유효하다.
결론: 게임의 혁신이 데이터센터를 바꾸다
AMD의 3D V-Cache는 처음 “게임용 CPU 기술"로 출발했지만, 실제 벤치마크와 프로덕션 환경 데이터는 캐시 친화성이라는 근본적 특성이 게임뿐만 아니라 서버, HPC, EDA 등 광범위한 분야에 적용 가능함을 입증했다.
핵심 통찰:
- 게임: 20~54% 성능 향상, 최소 FPS 안정화
- Redis: 110% 이상 처리량 향상, 2배 전력 효율
- Cloudflare: 145% 처리량, 50% 노드 감소
- CFD: 2배 성능, 슈퍼리니어 스케일링
더는 3D V-Cache를 “게이머 전용 기술"이라 할 수 없다. 그것은 메모리 접근 지연이 성능을 결정하는 모든 워크로드의 패러다임 변화를 의미하며, CPU 아키텍처 선택 기준 자체를 재정의했다.
참고
- AMD - 3D V-Cache 기술 소개
- Gamers Nexus - AMD Ryzen 9 9950X3D CPU 리뷰 & 벤치마크
- Principled Technologies - EPYC 9004 프로세서 & Redis 경쟁력 분석
- Cloudflare’s 12th Generation servers — 145% more performant and 63% more efficient
- AMD - OpenFOAM & 3D V-Cache 기술
- AMD Performance brief - SYNOPSYS® VCS® PERFORMANCE UPLIFTS