
기존의 많은 Go 개발자들은 sync.Pool의 성능 이점을 의심해왔다. “정말 그렇게까지 빠를까?”, “소규모 프로젝트에서도 필요할까?“라는 회의적인 질문이 반복되었다. 하지만 진짜 시나리오에서의 벤치마크는 sync.Pool이 결코 과대평가된 도구가 아님을 명확히 보여준다.
벤치마크 설정: 현실적인 워크로드
이 분석은 다음 조건에서 수행되었다:
- 할당 방식: Slice 기반 버퍼 (Go에서 가장 일반적)
- 배치 크기: 1회 반복당 1,000개 객체 할당 및 반환
- 할당 크기: 32바이트 ~ 131,072바이트 (7단계)
- 동시성: GOMAXPROCS=1 (단일 스레드) vs GOMAXPROCS=8 (8개 P 병렬 처리)
중요한 점은 버퍼를 재사용 가능한 슬라이스에 저장해 실제 애플리케이션의 풀 캐시 효율을 반영했다는 것이다.
주요 발견: 크기별 성능 격차
1. 단일 스레드(GOMAXPROCS=1)에서도 상당한 개선
| 할당 크기 | Make(ns/op) | SyncPool(ns/op) | 개선율 |
|---|---|---|---|
| 32B | 19,436 | 17,941 | 1.1x |
| 256B | 35,893 | 18,078 | 2.0x |
| 1KB | 108,946 | 18,095 | 6.0x |
| 4KB | 402,517 | 18,464 | 21.8x |
| 16KB | 1,984,701 | 18,657 | 106.4x |
| 64KB | 6,562,374 | 18,677 | 351.4x |
| 128KB | 11,345,907 | 18,156 | 624.9x |
단일 스레드 환경에서도 중간~대형 버퍼부터 엄청난 성능 차이가 발생한다. 특히 16KB 이상에서는 100배 이상의 차이가 나타난다. 이는 직접 할당(Make)이 메모리 클리어링(zeroing), GC 추적, 페이지 할당 등의 복잡한 작업을 수행하기 때문이다.
2. 병렬 환경(GOMAXPROCS=8)에서 극적인 개선
병렬 처리 환경에서 sync.Pool의 진정한 가치가 드러난다:
| 할당 크기 | Make(ns/op) | SyncPool(ns/op) | 개선율 |
|---|---|---|---|
| 32B | 18,687 | 4,261 | 4.4x |
| 256B | 72,857 | 8,535 | 8.5x |
| 1KB | 181,995 | 8,967 | 20.3x |
| 4KB | 599,625 | 9,499 | 63.1x |
| 16KB | 1,725,698 | 3,899 | 442.6x |
| 64KB | 4,657,615 | 3,816 | 1,220.5x |
| 128KB | 8,826,957 | 4,482 | 1,969.4x |
GOMAXPROCS=8에서는 대형 객체 할당 시 2,000배까지의 성능 향상을 기록했다. 이는 Make 방식이 모든 고루틴에서 메모리 할당을 두고 경합하면서 겪는 GC assist 및 락 경합 때문이다.
차트로 보는 성능 격차
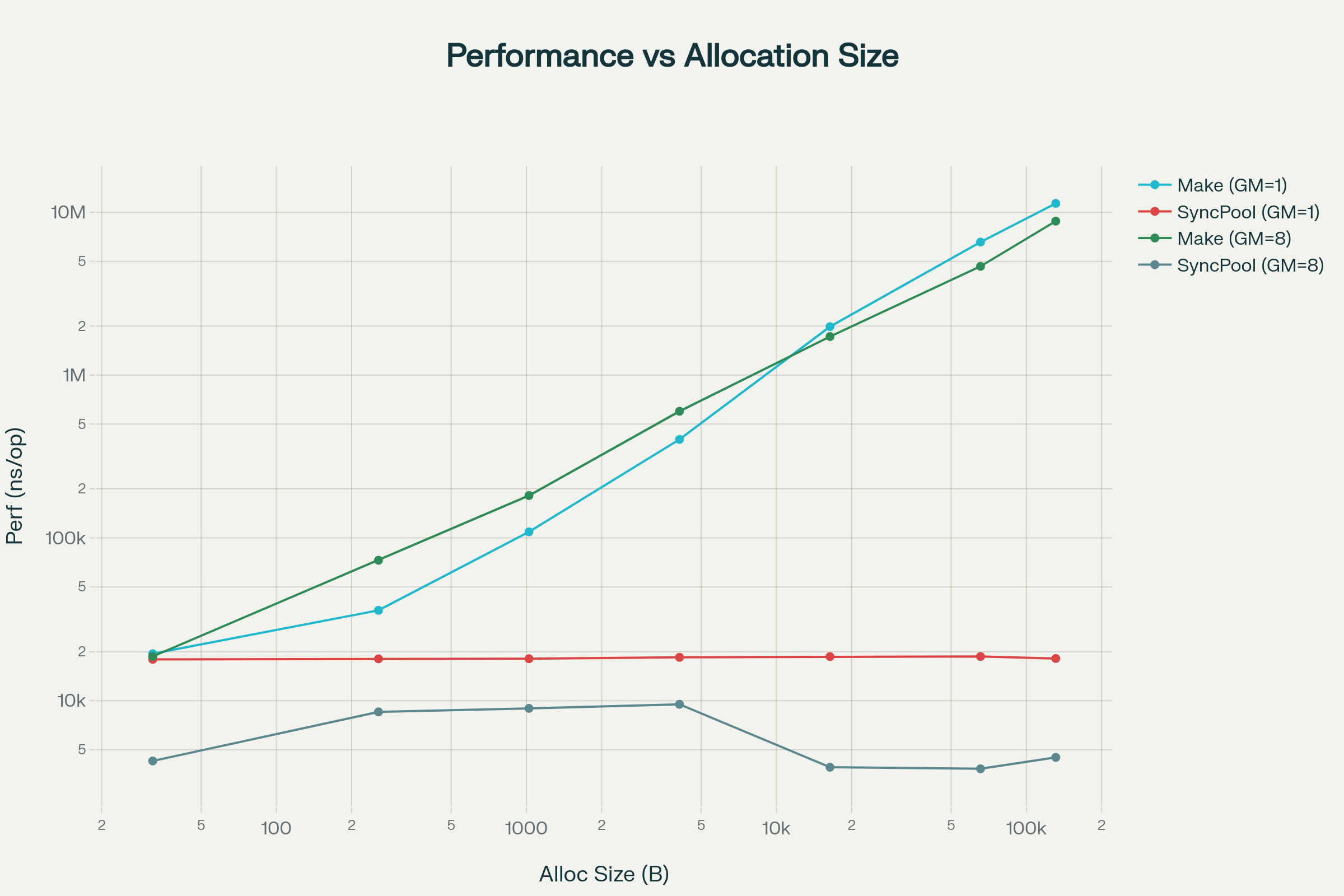
절대 성능 비교 (로그 스케일, 더 낮을수록 빠름):
성능 개선 비율 (로그 스케일):
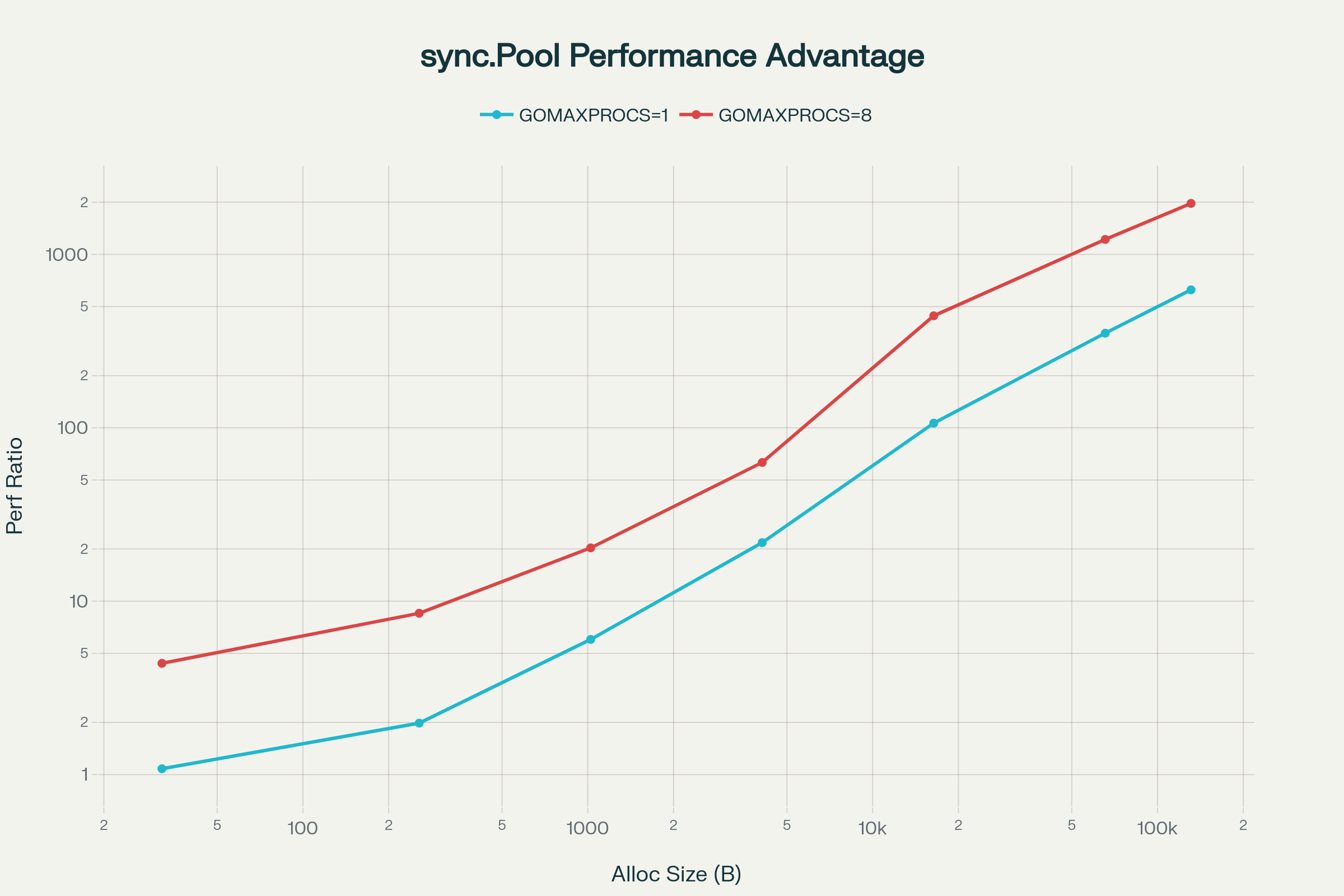
차트에서 볼 수 있듯이 크기가 증가할수록 비선형적으로 개선율이 커진다. GOMAXPROCS=8에서는 더 급격한 차이가 발생하는데, 이는 멀티코어 환경에서 GC와 메모리 할당 경합이 얼마나 심한지 보여준다. sync.Pool의 성능은 거의 크기 무관하게 일정한 반면(~18μs), Make는 크기에 따라 기하급수적으로 느려진다.
로그 스케일 차트에서는 더 명확하게 두 접근 방식의 격차를 시각적으로 확인할 수 있다. 큰 할당 크기에서 Make와 SyncPool 선 사이의 수직 거리가 극적으로 벌어진다.
왜 이런 차이가 나는가?
Make의 비용 구조
직접 할당(make([]byte, size))은 다음 단계를 거친다:
메모리 페이지 할당 (크기 기반 비용), 전체 메모리 클리어링(Zeroing), GC 메타데이터 업데이트, GC 추적 시스템 포함, 그리고 병렬 환경에서는 GC assist 트리거 및 전역 락 경합까지 발생한다.
크기가 크면 클수록 클리어링 작업의 양이 선형적으로 증가하고, GC 압력이 커져 GC assist 확률이 증가하며(모든 고루틴 중단 가능), 멀티코어 환경에서 할당 락 경합이 발생한다.
sync.Pool의 효율성
pool.Get()은 로컬 P 전용 저장소 확인(매우 빠름, 락 없음)과 이미 클리어된 상태의 객체 반환을 수행한다.
pool.Put(obj)은 로컬 P 저장소에 직접 저장(락 없음)하고 다음 Get에서 재사용 가능하게 한다.
sync.Pool의 이점은 락 프리(lock-free) per-P 스토리지 사용, 메모리 클리어링 불필요(이미 정리된 상태), GC 추적 바깥(세대별 청소 후에만 버림), 크기 무관한 성능(포인터 get/put만)이다.
실무 영향: 언제 중요한가?
sync.Pool이 필수인 경우
WebSocket/네트워크 서버: 요청마다 수KB 버퍼 할당 & GC 압력 높음 → 개선율 100~500배 (GOMAXPROCS 높을수록)
메시지 큐 시스템: 수만 개 메시지의 동시 처리 → 개선율 1,000배 이상 (64KB+ 메시지)
고성능 데이터 처리: 배치 처리 중 임시 버퍼 빈번 사용 → 개선율 200~600배
실시간 게임 서버: 게임 틱당 수백 개 할당 → 개선율 500배 이상 (누적 효과)
반대로 sync.Pool이 불필요한 경우
초소형 객체 (< 32바이트): 개선율 1~2배, 오버헤드가 더 클 수 있음
할당 빈도 낮음: 초당 수십 번 미만의 할당
싱글 고루틴 + 소형 버퍼: 1~2배 개선도 의미 없음
실제 적용 전략
1. 측정 먼저
프로덕션 배포 전에 항상 벤치마크를 통해 검증해야 한다. 대상 객체의 실제 크기, 할당 패턴, 병렬성을 고려해 sync.Pool 도입이 정당한지 확인한다.
2. 크기 기반 선택
작은 객체(< 256B)의 경우 풀 오버헤드가 크므로 직접 할당이 낫다. 중간 크기(256B ~ 16KB)에서는 풀 사용을 권장하며(4~22배 개선), 대형 객체(> 16KB)의 경우 풀은 필수이다(100~2000배 개선).
3. 프로필링으로 검증
벤치마크 후 실제 프로필링으로 메모리 할당이 병목인지 확인한다. go test -benchmem -bench=. .로 할당 횟수와 메모리 사용량을 추적한다.
결론
sync.Pool은 과대평가가 아니라 저평가된 도구이다.이 벤치마크 결과는 명확하다:
✅ 4KB 이상: 반드시 sync.Pool 사용 (20~100배 개선 최소)
✅ 16KB 이상: 성능 필수 (100~2,000배 개선)
✅ 병렬 환경: sync.Pool 사용 거의 필수 (개선율 2~10배 증가)
⚠️ 작은 객체: 프로필링 후 판단 (오버헤드 가능)
⚠️ 싱글 스레드: 상대적으로 개선율 낮음 (하지만 여전히 효과 있음)
현대의 Go 백엔드 시스템은 대부분 멀티코어 병렬 환경에서 실행된다. 이런 환경에서 sync.Pool은 단순한 성능 최적화가 아니라 필수적인 아키텍처 패턴이다.
다음 번 프로젝트에서 임시 메모리를 다룰 때는, sync.Pool을 먼저 고려하라. 이 차트의 숫자들이 그것의 가치를 충분히 증명한다.
벤치마크 코드
package makevssyncpool
import (
"fmt"
"sync"
"testing"
)
func BenchmarkAllocations(b *testing.B) {
// Define various allocation sizes.
allocSizes := []int{32, 256, 1024, 4096, 16384, 65536, 131072}
numAllocsLevels := []int{100, 1000} // Number of objects to allocate at once.
for _, numAllocs := range numAllocsLevels {
b.Run(fmt.Sprintf("NumAllocs_%d", numAllocs), func(b *testing.B) {
// --- Warm-up before starting benchmarks ---
// Pre-activate the pool for the largest size (131072) to reduce benchmark distortion.
b.Logf("Warming up the pool with size 131072 for numAllocs %d...", numAllocs)
warmupPool := sync.Pool{
New: func() interface{} {
buf := make([]byte, 131072)
return &buf
},
}
warmupBufs := make([]*[]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
warmupBufs[i] = warmupPool.Get().(*[]byte)
}
for i := 0; i < numAllocs; i++ {
warmupPool.Put(warmupBufs[i])
}
// --- Byte Slice Benchmarks ---
b.Run("Slice", func(b *testing.B) {
// 1. Performance measurement using make([]byte, size)
b.Run("Make", func(b *testing.B) {
for _, size := range allocSizes {
b.Run(fmt.Sprintf("Size_%d", size), func(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
// Prevent compiler optimization by storing the result in a slice.
s := make([][]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = make([]byte, size)
}
}
})
})
}
})
// 2. Performance measurement using sync.Pool (*[]byte)
b.Run("SyncPool", func(b *testing.B) {
for _, size := range allocSizes {
b.Run(fmt.Sprintf("Size_%d", size), func(b *testing.B) {
pool := sync.Pool{
New: func() interface{} {
buf := make([]byte, size)
return &buf
},
}
b.RunParallel(func(pb *testing.PB) {
// Create a buffer slice for Get/Put only once.
bufs := make([]*[]byte, numAllocs)
for pb.Next() {
for i := 0; i < numAllocs; i++ {
bufs[i] = pool.Get().(*[]byte)
}
for i := 0; i < numAllocs; i++ {
pool.Put(bufs[i])
}
}
})
})
}
})
})
// --- Byte Array Benchmarks ---
b.Run("Array", func(b *testing.B) {
// 1. Performance measurement using new([N]byte)
b.Run("New", func(b *testing.B) {
for _, size := range allocSizes {
b.Run(fmt.Sprintf("Size_%d", size), func(b *testing.B) {
switch size {
case 32:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
// Prevent compiler optimization by storing the result in a slice.
s := make([]*[32]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([32]byte)
}
}
})
case 256:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[256]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([256]byte)
}
}
})
case 1024:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[1024]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([1024]byte)
}
}
})
case 4096:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[4096]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([4096]byte)
}
}
})
case 16384:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[16384]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([16384]byte)
}
}
})
case 65536:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[65536]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([65536]byte)
}
}
})
case 131072:
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
s := make([]*[131072]byte, numAllocs)
for i := 0; i < numAllocs; i++ {
s[i] = new([131072]byte)
}
}
})
}
})
}
})
// 2. Performance measurement using sync.Pool (*[N]byte)
b.Run("SyncPool", func(b *testing.B) {
for _, size := range allocSizes {
b.Run(fmt.Sprintf("Size_%d", size), func(b *testing.B) {
switch size {
case 32:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([32]byte) }})
case 256:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([256]byte) }})
case 1024:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([1024]byte) }})
case 4096:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([4096]byte) }})
case 16384:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([16384]byte) }})
case 65536:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([65536]byte) }})
case 131072:
runArrayPoolBenchmark(b, numAllocs, sync.Pool{New: func() interface{} { return new([131072]byte) }})
}
})
}
})
})
})
}
}
func runArrayPoolBenchmark(b *testing.B, numAllocs int, pool sync.Pool) {
b.RunParallel(func(pb *testing.PB) {
// Create a buffer slice for Get/Put only once.
bufs := make([]interface{}, numAllocs)
for pb.Next() {
for i := 0; i < numAllocs; i++ {
bufs[i] = pool.Get()
}
for i := 0; i < numAllocs; i++ {
pool.Put(bufs[i])
}
}
})
}