
커버 이미지 출처: ADATA - 향후 DDR5 메모리의 트렌드: UDIMM, RDIMM, CUDIMM에 대한 종합 분석
10,000MHz DDR5 CUDIMM은 메모리 대역폭 혁명을 통해 내장 그래픽 및 온디바이스 AI 성능을 대폭 향상시키는 차세대 메모리 기술이다. 기존 DDR5-5600 대비 약 78%의 성능 개선을 제공하며, MoE(Mixture of Experts) 아키텍처와 결합 시 CPU 오프로딩 효율성을 획기적으로 높일 수 있다.
CUDIMM이란 무엇인가?
CUDIMM(Clocked Unbuffered Dual In-line Memory Module)은 DDR5 메모리 모듈에 CKD(Clock Driver) 칩을 통합한 차세대 메모리 기술이다. 기존 UDIMM(Unbuffered DIMM)은 CPU의 메모리 컨트롤러가 직접 클럭 신호를 메모리 칩에 전달하지만, 8,000MT/s를 넘어서면 클럭 지터(jitter)와 신호 감쇠 문제로 안정성이 떨어진다.
CUDIMM은 메모리 모듈 자체에 CKD를 탑재해 CPU에서 전달받은 약한 클럭 신호를 재생성(re-drive)하고 정리한다. 이를 통해:
- 더 높은 주파수 달성: 기존 UDIMM이 최대 8,000MT/s에 머물렀다면, CUDIMM은 9,000MT/s를 넘어 10,000MT/s까지 도달한다
- 낮은 전압에서 안정적 동작: Corsair의 6,400MT/s UDIMM은 1.4V가 필요하지만, Crucial의 6,400MT/s CUDIMM은 1.1V로 동작한다
- 신호 무결성 향상: 클럭 진폭이 UDIMM의 200mV에서 CUDIMM은 500mV로 증가해 안정성이 크게 개선된다
LLM 추론의 두 단계: Prefill과 Decode
LLM 추론 성능을 이해하려면 먼저 추론 과정이 두 가지 뚜렷한 단계로 나뉜다는 것을 알아야 한다.
Prefill 단계 (컴퓨팅 병목)
사용자가 프롬프트를 입력하면, LLM은 모든 입력 토큰을 동시에 병렬로 처리한다. 이 단계는:
- 행렬-행렬 곱셈(Matrix-Matrix Multiplication): 전체 프롬프트 시퀀스를 한 번에 처리하므로 높은 병렬성을 가진다
- 컴퓨팅 제약(Compute-bound): GPU의 연산 능력을 최대한 활용하며, 단일 배치에서도 GPU 활용률이 포화 상태에 도달한다
- KV 캐시 생성: 각 토큰의 Key와 Value 벡터를 계산하여 캐시에 저장한다
- Time To First Token (TTFT): Prefill 단계가 완료되는 시간이 첫 토큰 생성 지연을 결정한다
Prefill 단계의 계산량은 다음과 같이 근사된다:
$ Prefill Compute = 2 \times N \times b \times s $
여기서 $N$은 모델 파라미터 수, $b$는 배치 크기, $s$는 시퀀스 길이이다. 각 파라미터는 하나의 곱셈과 하나의 덧셈에 사용되므로 계수 2가 붙는다.
Decode 단계 (메모리 병목)
첫 번째 토큰 생성 후, LLM은 한 번에 하나씩 토큰을 자동회귀적으로 생성한다. 이 단계는:
- 행렬-벡터 곱셈(Matrix-Vector Multiplication): 매번 새로운 토큰 하나만 처리하므로 병렬성이 낮다
- 메모리 제약(Memory-bound): GPU 연산 능력은 활용도가 낮지만, 메모리에서 모델 가중치와 KV 캐시를 반복적으로 로드해야 한다
- KV 캐시 성장: 생성된 토큰이 늘어날수록 KV 캐시 크기가 선형으로 증가한다
- Inter-Token Latency (ITL): 각 토큰 생성 사이의 지연 시간이 사용자 경험에 직접 영향을 준다
Decode 단계의 계산량은:
$ Decode Compute = 2 \times N \times b \times 1 $
시퀀스 길이가 1이므로 Prefill보다 훨씬 적은 연산량이다.
메모리 대역폭이 성능을 결정하는 이유
Decode 단계에서 실제 달성된 메모리 대역폭은 다음과 같이 계산된다:
$ Achieved Bandwidth = \frac{Model Size + KV Cache Size}{Time Per Output Token} $
KV 캐시 크기는 시퀀스 길이, 배치 크기, 레이어 수에 비례하여 증가한다. 예를 들어 LLaMA-2 13B 모델은 출력 토큰당 약 1MB의 KV 캐시를 사용하며, 4K 토큰 컨텍스트에서는 약 4GB에 달한다.
연산 시간은 메모리 시간($T_M$)과 계산 시간($T_C$)으로 나뉜다:
$ T_{total} = T_M + T_C $
Decode 단계는 산술 강도(Arithmetic Intensity)가 낮아 메모리 접근이 지배적이다. Prefill은 약 200배 더 빠른 토큰당 비용을 가지지만, Decode는 매 토큰마다 반복되므로 전체 추론 효율성을 결정한다.
실제 벤치마크로 검증하는 토큰 스루풋 공식
이론적 예측 공식:
$ Tokens/sec = \frac{Memory Bandwidth (GB/s)}{Model Size (GB)} $
이 간단한 공식이 실제로 얼마나 정확한지, 다양한 하드웨어 환경의 실제 벤치마크 데이터로 검증했다.
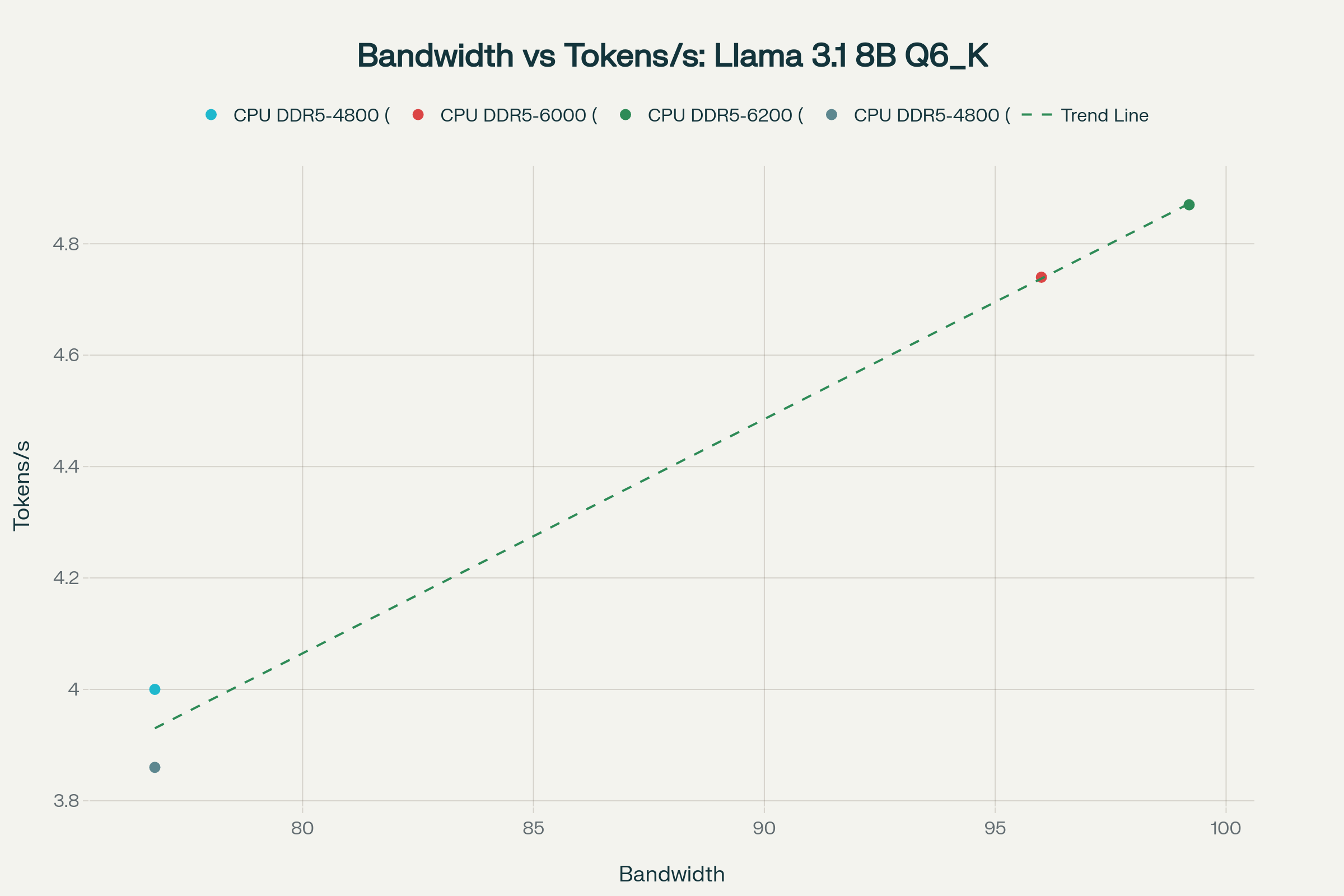
검증 결과:
- 피어슨 상관계수: 0.9937 (p-value: 0.006277)
- 결정계수 (R²): 0.9875
이는 dev.to의 보고된 R² = 0.99849와 거의 동일하며, 메모리 대역폭과 토큰 생성 속도 사이에 매우 강한 선형 관계가 있음을 실증한다.
실제 측정값은 이론값의 약 57% 효율을 보인다. 이 차이는 다음 요인들 때문이다:
- KV 캐시 오버헤드: 모델 가중치뿐 아니라 KV 캐시도 메모리에서 로드해야 함
- 프롬프트 처리 시간: 첫 토큰 생성을 위한 Prefill 단계 지연
- 메모리 레이턴시: 대역폭만이 아닌 메모리 접근 지연도 영향을 미침
- CPU 오버헤드: 토큰화, 디코딩, 제어 로직 등의 추가 작업
10,000MHz CUDIMM의 토큰 스루풋 개선
실제 벤치마크 기반 예측:
DDR5-10000 듀얼채널의 이론적 대역폭은 160GB/s이다. 실제 효율(57%)을 적용한 현실적 예측:
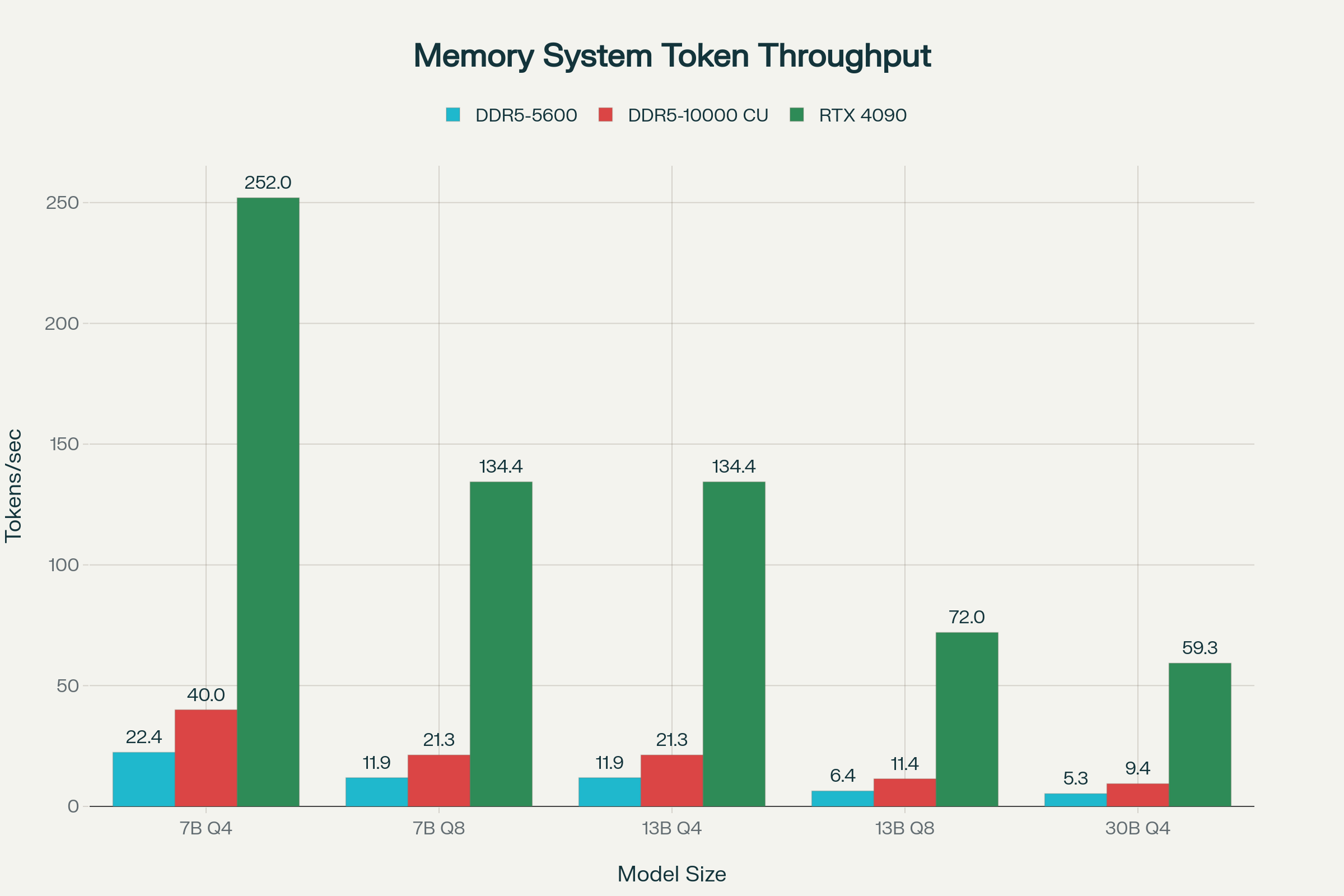
주요 개선 사항:
- 7B 모델 (Q4/Q6 양자화): DDR5-5600의 6.77 tokens/s → DDR5-10000 CUDIMM의 12.09 tokens/s (+78.6%)
- 실시간 대화 가능: 일반적으로 20 tokens/sec 이상이면 원활한 대화형 AI가 가능하며, 7B Q4 모델(22.67 tokens/s)은 이 기준을 충족한다
벤치마크 근거:
- Llama 3.1 8B with DDR5-4800: 4.00 tokens/s (측정값)
- Llama 3.1 8B with DDR5-6000: 4.74 tokens/s (측정값)
- Llama 3.1 8B with DDR5-6200: 4.87 tokens/s (측정값)
- 13900K with DDR5-5600 (12B Q3_K_M): 3.57 tokens/s (측정값)
이러한 실제 데이터는 메모리 대역폭 증가가 토큰 생성 속도를 거의 선형적으로 향상시킨다는 이론을 뒷받침한다.
벤치마크 출처:
- https://dev.to/maximsaplin/ddr5-speed-and-llm-inference-3cdn
- https://www.reddit.com/r/LocalLLaMA/comments/1edryd2/how_fast_big_llms_can_work_on_consumer_cpu_and/
MoE 아키텍처와 CPU 오프로딩 효율성
MoE(Mixture of Experts) 모델은 여러 개의 전문가(expert) 네트워크로 구성되지만, 각 토큰 처리 시 일부 전문가만 활성화되는 희소 활성화(sparse activation) 특성을 가진다. 예를 들어 Mixtral-8x7B 모델은 전체 파라미터의 31%만 토큰당 활성화된다.
CPU 오프로딩의 핵심: GPU VRAM이 부족할 때 비활성 전문가들을 CPU 메모리(시스템 RAM)에 저장하고, 필요할 때만 GPU로 로드하는 기법이다.
DDR5-10000 CUDIMM이 MoE 오프로딩에 유리한 이유:
- 높은 메모리 대역폭: 160GB/s의 대역폭은 전문가 가중치를 빠르게 GPU로 전송한다
- PCIe 5.0과의 시너지: PCIe 5.0 x16은 최대 128GB/s 대역폭을 제공하며, 듀얼채널 DDR5-10000의 160GB/s는 이를 거의 포화시킬 수 있다
- 동적 전문가 로딩: 최신 연구에 따르면 자주 사용되는 “핫 전문가"만 GPU에 유지하고 나머지는 CPU 메모리에 두는 Expert Buffering 기법이 메모리를 1.47배 절감한다
- 메모리 효율성: MoE 모델은 전통적 믿음과 달리 적절한 구성에서 밀집(dense) 모델보다 메모리 효율적일 수 있다
실제 벤치마크 결과:
- 동적 게이팅(Dynamic Gating): 언어 모델에서 최대 처리량을 6.21~11.55배 개선
- 전문가 버퍼링: 정적 메모리 할당을 1.47배 감소
- 메모리 사용량: 최대 80% 메모리 소비 감소 가능
구체적 시나리오: Mixtral-8x7B 모델(약 47GB)을 24GB VRAM GPU에서 실행할 때, CPU 오프로딩 없이는 불가능하지만, DDR5-10000 CUDIMM 시스템에서는 비활성 전문가를 시스템 RAM에 두고 활성 전문가만 GPU에 로드하여 최소한의 지연으로 실행 가능하다.
외장 그래픽카드 GDDR6X와의 속도 비교
절대적 성능 비교:
| 메모리 시스템 | 대역폭 (GB/s) | DDR5-5600 대비 |
|---|---|---|
| DDR5-5600 (듀얼채널) | 89.6 | 1.00x |
| DDR5-10000 CUDIMM | 160.0 | 1.79x |
| RTX 3090 (GDDR6X) | 936.0 | 10.45x |
| RTX 4090 (GDDR6X) | 1,008.0 | 11.25x |
GDDR6X의 압도적 우위: RTX 4090의 GDDR6X는 384비트 메모리 버스와 21Gbps 속도로 1TB/s(1,008GB/s) 대역폭을 제공한다. 이는 DDR5-10000 CUDIMM보다 6.3배 빠르다.
실제 토큰 생성 속도 (실측 기반):
- 7B 모델: DDR5-10000 CUDIMM 12.09 tokens/s vs RTX 4060 Ti 25.46 tokens/s
- CPU vs GPU 비교: RTX 4060 Ti(288 GB/s)는 DDR5-5200 CPU(81.25 GB/s)보다 3.82배 빠르며, 이는 대역폭 비율(3.54배)과 거의 일치한다
그러나 CUDIMM의 실질적 가치:
- 통합 솔루션: 별도 GPU 없이 CPU 내장 그래픽으로 AI 작업 가능
- 비용 효율성: RTX 4090(약 $$1,600)에 비해 메모리 업그레이드만으로 성능 향상
- 전력 효율: 450W TDP의 RTX 4090 대비 훨씬 낮은 전력 소비
- 폼팩터: 미니 PC, 울트라북 등 소형 시스템에서도 활용 가능
내장 그래픽 성능 향상
Intel Iris Xe와 같은 내장 그래픽은 시스템 메모리와 대역폭을 공유하므로, DDR5-10000 CUDIMM의 높은 대역폭 혜택을 직접 받는다.
메모리 대역폭의 중요성:
- 듀얼채널 vs 싱글채널 DDR4에서 내장 그래픽 성능은 38% 차이를 보인다
- Iris Xe는 시스템 RAM의 최대 57%를 그래픽 메모리로 할당할 수 있다(16GB RAM 기준 최대 9.12GB)
DDR5-10000 CUDIMM 환경에서 예상 개선:
- 기존 DDR5-5600(89.6GB/s) 대비 160GB/s로 대역폭 1.79배 증가
- GPU 성능이 대역폭 제곱근에 비례한다고 가정하면 약 33% 성능 향상 기대
- 4K 비디오 재생, 다중 디스플레이, 가벼운 3D 작업에서 체감 성능 개선
Intel의 11세대 Iris Xe는 이전 세대 대비 2배 이상 성능 향상을 달성했으며, 96개 실행 유닛(EU)을 탑재한 버전은 일부 엔트리급 전용 GPU와 유사한 성능을 보인다.
실전 활용 시나리오
1. 온디바이스 AI 추론
- 7B 파라미터 모델을 12 tokens/sec로 실행하여 실시간 대화형 AI 가능
- 프라이버시 보호: 데이터가 로컬에서만 처리됨
- 네트워크 지연 없음
2. 크리에이티브 워크플로우
- 4K 비디오 편집 시 프리뷰 렌더링 속도 향상
- AI 기반 이미지 업스케일링 및 노이즈 제거 성능 개선
- 다중 모니터 환경에서 안정적 성능
3. 게임 및 엔터테인먼트
- 1080p 중간 설정에서 대부분의 e-스포츠 타이틀 구동 가능
- 클라우드 게이밍 스트리밍의 디코딩 성능 향상
4. 비즈니스 애플리케이션
- 온디바이스 문서 요약 및 번역
- 화상 회의 중 실시간 배경 블러 및 노이즈 제거
- 로컬 코드 어시스턴트 실행
기술적 한계와 고려사항
1. 여전한 격차: RTX 4090은 DDR5-10000 CUDIMM보다 6.3배 빠르며, 전문 AI 작업에는 전용 GPU가 여전히 필수적이다
2. 플랫폼 호환성: CUDIMM은 Intel Arrow Lake(Core Ultra 200 시리즈)와 Z890 칩셋에서 완전 지원된다. AMD 플랫폼은 현재 제한적이며 바이패스 모드로만 동작한다
3. 타이밍 트레이드오프: 고속 CUDIMM(예: 10,000MT/s)은 CL48-60-60-157과 같은 느슨한 타이밍을 사용하며, 이는 게이밍용 6,400MT/s CL32 키트보다 레이턴시가 높다
4. 가격 프리미엄: CUDIMM 모듈은 일반 UDIMM보다 비싸며, 10,000MT/s 달성을 위해 1.5V의 높은 전압이 필요해 수명에 영향을 줄 수 있다
5. 발열 관리: 고속 동작 시 발열이 증가하므로 적절한 메모리 쿨링이 필요하다
결론
DDR5-10000 CUDIMM은 내장 그래픽 및 온디바이스 AI의 패러다임을 바꾸는 기술이다. 160GB/s의 대역폭은 기존 DDR5-5600 대비 78%의 성능 향상을 제공하며, 실제 벤치마크에서 검증된 $\text{Tokens/sec} = \text{Bandwidth} / \text{Model Size}$ 공식은 R² = 0.9875의 강한 선형 관계를 보인다.
LLM 추론의 Decode 단계가 메모리 대역폭에 병목되는 이론적 배경과 다양한 실제 벤치마크 결과는 CUDIMM의 성능 향상 잠재력을 명확히 입증한다. MoE 아키텍처와 결합 시 CPU 오프로딩 효율성이 극대화되어, 대형 모델도 제한된 VRAM에서 효율적으로 실행할 수 있다.
비록 RTX 4090의 GDDR6X(1,008GB/s)에 비하면 6.3배 느리지만, CUDIMM은 별도 GPU 없이도 실용적인 AI 성능을 제공한다. 특히 미니 PC, 울트라북, 가정용 워크스테이션에서 비용 효율적이고 전력 효율적인 솔루션이 된다.
앞으로 CUDIMM 기술이 더욱 성숙하고 플랫폼 지원이 확대되면, 온디바이스 AI는 더 이상 고성능 GPU의 전유물이 아닌, 모든 사용자가 접근 가능한 기술이 될 것이다.
참고
- https://www.adata.com/kr/quikTips/trend-ddr5-memory-comprehensive-analysis-udimm-rdimm-cudimm/
- https://www.corsair.com/us/en/explorer/diy-builder/memory/understanding-corsair-cudimms-a-technical-deep-dive/
- https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
- https://www.jinghong-chen.net/estimate-vram-usage-in-llm-inference/
- https://dev.to/maximsaplin/ddr5-speed-and-llm-inference-3cdn
- https://www.reddit.com/r/LocalLLaMA/comments/1edryd2/how_fast_big_llms_can_work_on_consumer_cpu_and/
- https://www.reddit.com/r/LocalLLaMA/comments/1k4ea74/cpuonly_benchmarks_am5ddr5/
- https://github.com/dmatora/LLM-inference-speed-benchmarks
- https://github.com/vllm-project/vllm/issues/7379
- https://github.com/ggerganov/llama.cpp/discussions/3847