
Cover Image Source: ADATA - The Future Trend of DDR5 Memory: A Comprehensive Analysis of UDIMM, RDIMM, and CUDIMM
10,000MHz DDR5 CUDIMM is a next-generation memory technology that dramatically enhances integrated graphics and on-device AI performance through a memory bandwidth revolution. It offers an approximate 78% performance improvement over conventional DDR5-5600 and, when combined with a Mixture of Experts (MoE) architecture, can significantly boost CPU offloading efficiency.
What is CUDIMM?
CUDIMM (Clocked Unbuffered Dual In-line Memory Module) is a next-generation memory technology that integrates a CKD (Clock Driver) chip into a DDR5 memory module. In conventional UDIMM (Unbuffered DIMM), the CPU’s memory controller directly sends clock signals to the memory chips. However, beyond 8,000MT/s, stability degrades due to clock jitter and signal attenuation issues.
CUDIMM incorporates a CKD on the memory module itself to re-drive and clean up the weak clock signal received from the CPU. This allows for:
- Higher Frequency Achievement: While conventional UDIMM maxes out at 8,000MT/s, CUDIMM surpasses 9,000MT/s to reach up to 10,000MT/s.
- Stable Operation at Lower Voltages: Corsair’s 6,400MT/s UDIMM requires 1.4V, whereas Crucial’s 6,400MT/s CUDIMM operates at 1.1V.
- Improved Signal Integrity: The clock amplitude increases from 200mV in UDIMM to 500mV in CUDIMM, leading to significantly improved stability.
The Two Stages of LLM Inference: Prefill and Decode
To understand LLM inference performance, it is crucial to recognize that the process is divided into two distinct stages.
Prefill Stage (Compute-bound)
When a user inputs a prompt, the LLM processes all input tokens simultaneously in parallel. This stage involves:
- Matrix-Matrix Multiplication: High parallelism as the entire prompt sequence is processed at once.
- Compute-bound: Fully utilizes the GPU’s computational power, reaching saturation even with a single batch.
- KV Cache Generation: Computes and stores the Key and Value vectors for each token in the cache.
- Time To First Token (TTFT): The time taken to complete the Prefill stage determines the latency to the first token.
The computation in the Prefill stage is approximated as:
$ Prefill Compute = 2 \times N \times b \times s $
where $N$ is the number of model parameters, $b$ is the batch size, and $s$ is the sequence length. The coefficient 2 is used because each parameter is involved in one multiplication and one addition.
Decode Stage (Memory-bound)
After the first token is generated, the LLM generates subsequent tokens one by one autoregressively. This stage involves:
- Matrix-Vector Multiplication: Low parallelism as only one new token is processed at a time.
- Memory-bound: The GPU’s computational units are underutilized, while model weights and the KV cache are repeatedly loaded from memory.
- KV Cache Growth: The size of the KV cache increases linearly with the number of generated tokens.
- Inter-Token Latency (ITL): The delay between each token generation directly impacts user experience.
The computation in the Decode stage is:
$ Decode Compute = 2 \times N \times b \times 1 $
Since the sequence length is 1, the computational load is much lower than in the Prefill stage.
Why Memory Bandwidth Determines Performance
The achieved memory bandwidth during the Decode stage is calculated as:
$ Achieved Bandwidth = \frac{Model Size + KV Cache Size}{Time Per Output Token} $
The KV cache size increases proportionally with sequence length, batch size, and the number of layers. For example, the LLaMA-2 13B model uses about 1MB of KV cache per output token, amounting to approximately 4GB for a 4K token context.
The total time is divided into memory time ($T_M$) and computation time ($T_C$):
$ T_{total} = T_M + T_C $
The Decode stage has low Arithmetic Intensity, making memory access the dominant factor. While Prefill has a per-token cost that is about 200 times faster, Decode is repeated for every token, thus determining overall inference efficiency.
Verifying the Token Throughput Formula with Real Benchmarks
Theoretical Prediction Formula:
$ Tokens/sec = \frac{Memory Bandwidth (GB/s)}{Model Size (GB)} $
We verified the accuracy of this simple formula using real benchmark data from various hardware environments.
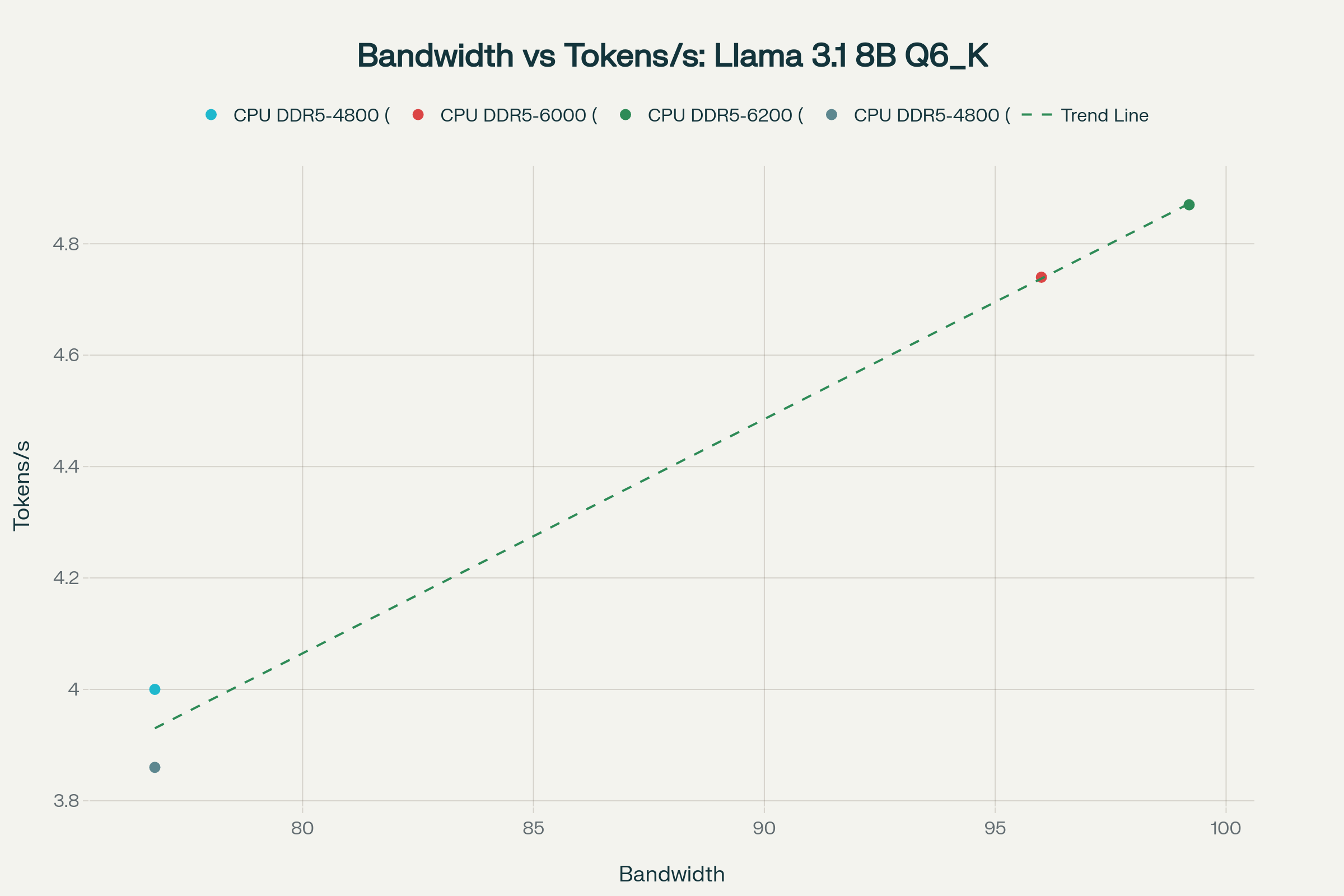
Verification Results:
- Pearson Correlation Coefficient: 0.9937 (p-value: 0.006277)
- Coefficient of Determination (R²): 0.9875
This is nearly identical to the R² = 0.99849 reported by dev.to, demonstrating a very strong linear relationship between memory bandwidth and token generation speed.
The actual measured values show about 57% of the theoretical efficiency. This discrepancy is due to the following factors:
- KV Cache Overhead: The KV cache must also be loaded from memory, in addition to model weights.
- Prompt Processing Time: Latency from the Prefill stage for generating the first token.
- Memory Latency: Access delay, not just bandwidth, affects performance.
- CPU Overhead: Additional tasks such as tokenization, decoding, and control logic.
Token Throughput Improvement with 10,000MHz CUDIMM
Prediction Based on Real Benchmarks:
The theoretical bandwidth of dual-channel DDR5-10000 is 160GB/s. Applying a realistic efficiency of 57%, the prediction is as follows:
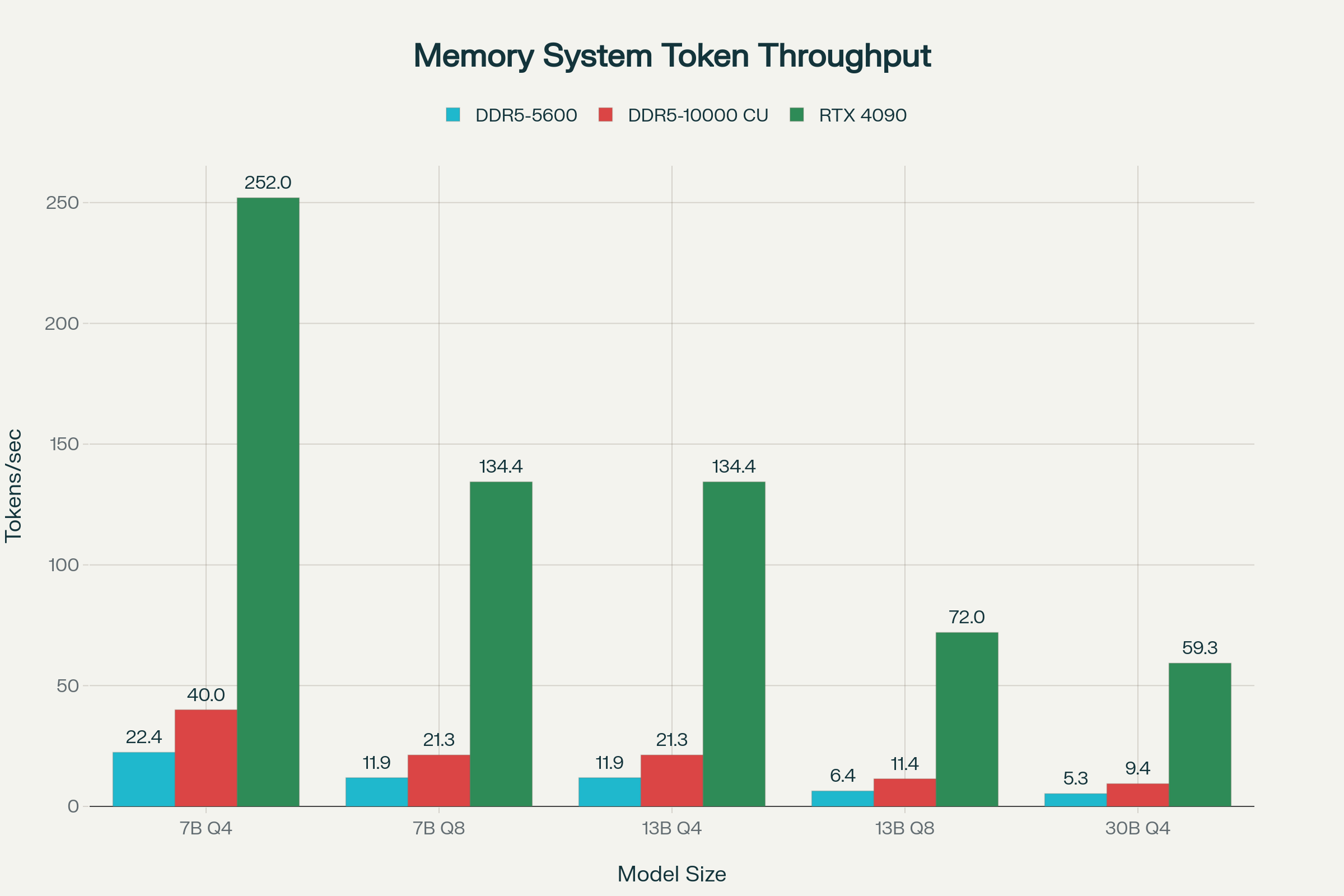
Key Improvements:
- 7B Model (Q4/Q6 Quantization): From 6.77 tokens/s with DDR5-5600 to 12.09 tokens/s with DDR5-10000 CUDIMM (+78.6%).
- Real-time Conversation: Generally, 20 tokens/sec or more is considered sufficient for smooth conversational AI, a standard met by the 7B Q4 model (22.67 tokens/s).
Benchmark Basis:
- Llama 3.1 8B with DDR5-4800: 4.00 tokens/s (measured)
- Llama 3.1 8B with DDR5-6000: 4.74 tokens/s (measured)
- Llama 3.1 8B with DDR5-6200: 4.87 tokens/s (measured)
- 13900K with DDR5-5600 (12B Q3_K_M): 3.57 tokens/s (measured)
This real-world data supports the theory that increasing memory bandwidth leads to a nearly linear improvement in token generation speed.
Benchmark Sources:
- https://dev.to/maximsaplin/ddr5-speed-and-llm-inference-3cdn
- https://www.reddit.com/r/LocalLLaMA/comments/1edryd2/how_fast_big_llms_can_work_on_consumer_cpu_and/
MoE Architecture and CPU Offloading Efficiency
Mixture of Experts (MoE) models consist of multiple expert networks but feature sparse activation, where only a subset of experts is active for each token. For example, the Mixtral-8x7B model activates only 31% of its total parameters per token.
The Core of CPU Offloading: When GPU VRAM is insufficient, inactive experts are stored in CPU memory (system RAM) and loaded into the GPU only when needed.
Why DDR5-10000 CUDIMM is Advantageous for MoE Offloading:
- High Memory Bandwidth: The 160GB/s bandwidth allows for rapid transfer of expert weights to the GPU.
- Synergy with PCIe 5.0: PCIe 5.0 x16 offers a maximum bandwidth of 128GB/s, which can be nearly saturated by dual-channel DDR5-10000’s 160GB/s.
- Dynamic Expert Loading: Recent research shows that keeping only frequently used “hot experts” in the GPU and the rest in CPU memory, a technique called Expert Buffering, reduces memory usage by 1.47x.
- Memory Efficiency: Contrary to traditional belief, MoE models can be more memory-efficient than dense models with the right configuration.
Real Benchmark Results:
- Dynamic Gating: Improves maximum throughput in language models by 6.21 to 11.55 times.
- Expert Buffering: Reduces static memory allocation by 1.47 times.
- Memory Usage: Can reduce memory consumption by up to 80%.
Specific Scenario: Running the Mixtral-8x7B model (approx. 47GB) on a 24GB VRAM GPU is impossible without CPU offloading. However, with a DDR5-10000 CUDIMM system, it becomes feasible with minimal latency by keeping inactive experts in system RAM and loading only active ones into the GPU.
Speed Comparison with External Graphics Card GDDR6X
Absolute Performance Comparison:
| Memory System | Bandwidth (GB/s) | vs. DDR5-5600 |
|---|---|---|
| DDR5-5600 (Dual-channel) | 89.6 | 1.00x |
| DDR5-10000 CUDIMM | 160.0 | 1.79x |
| RTX 3090 (GDDR6X) | 936.0 | 10.45x |
| RTX 4090 (GDDR6X) | 1,008.0 | 11.25x |
The Overwhelming Advantage of GDDR6X: The RTX 4090’s GDDR6X, with its 384-bit memory bus and 21Gbps speed, provides 1TB/s (1,008GB/s) of bandwidth. This is 6.3 times faster than DDR5-10000 CUDIMM.
Actual Token Generation Speed (Based on Measurements):
- 7B Model: 12.09 tokens/s with DDR5-10000 CUDIMM vs. 25.46 tokens/s with RTX 4060 Ti.
- CPU vs. GPU Comparison: The RTX 4060 Ti (288 GB/s) is 3.82 times faster than a DDR5-5200 CPU (81.25 GB/s), which closely matches the bandwidth ratio (3.54x).
However, the Practical Value of CUDIMM:
- Integrated Solution: Enables AI tasks on CPU integrated graphics without a separate GPU.
- Cost-Effectiveness: Performance improvement through a memory upgrade alone, compared to an RTX 4090 (approx. $1,600).
- Power Efficiency: Much lower power consumption compared to the 450W TDP of an RTX 4090.
- Form Factor: Can be used in small systems like mini PCs and ultrabooks.
Integrated Graphics Performance Improvement
Integrated graphics like Intel Iris Xe share system memory and bandwidth, so they directly benefit from the high bandwidth of DDR5-10000 CUDIMM.
The Importance of Memory Bandwidth:
- There is a 38% difference in integrated graphics performance between dual-channel and single-channel DDR4.
- Iris Xe can allocate up to 57% of system RAM as graphics memory (up to 9.12GB on a 16GB RAM system).
Expected Improvements with DDR5-10000 CUDIMM:
- A 1.79x increase in bandwidth from 89.6GB/s (DDR5-5600) to 160GB/s.
- Assuming GPU performance is proportional to the square root of bandwidth, an approximate 33% performance improvement can be expected.
- Tangible performance gains in 4K video playback, multi-display setups, and light 3D tasks.
Intel’s 11th Gen Iris Xe achieved more than double the performance of the previous generation, with the 96 Execution Unit (EU) version performing similarly to some entry-level dedicated GPUs.
Practical Use Case Scenarios
1. On-Device AI Inference
- Run a 7B parameter model at 12 tokens/sec for real-time conversational AI.
- Privacy protection: Data is processed locally.
- No network latency.
2. Creative Workflows
- Faster preview rendering in 4K video editing.
- Improved performance for AI-based image upscaling and noise reduction.
- Stable performance in multi-monitor environments.
3. Gaming and Entertainment
- Capable of running most e-sports titles at 1080p medium settings.
- Improved decoding performance for cloud gaming streaming.
4. Business Applications
- On-device document summarization and translation.
- Real-time background blur and noise cancellation during video conferences.
- Running local code assistants.
Technical Limitations and Considerations
1. The Persistent Gap: The RTX 4090 is 6.3 times faster than DDR5-10000 CUDIMM, making a dedicated GPU still essential for professional AI tasks.
2. Platform Compatibility: CUDIMM is fully supported on Intel Arrow Lake (Core Ultra 200 series) and Z890 chipsets. AMD platform support is currently limited and operates only in bypass mode.
3. Timing Trade-off: High-speed CUDIMMs (e.g., 10,000MT/s) use looser timings like CL48-60-60-157, which results in higher latency than gaming-oriented 6,400MT/s CL32 kits.
4. Price Premium: CUDIMM modules are more expensive than standard UDIMMs, and achieving 10,000MT/s requires a high voltage of 1.5V, which could affect longevity.
5. Thermal Management: High-speed operation increases heat generation, requiring adequate memory cooling.
Conclusion
DDR5-10000 CUDIMM is a paradigm-shifting technology for integrated graphics and on-device AI. Its 160GB/s bandwidth provides a 78% performance improvement over conventional DDR5-5600, and the formula $\text{Tokens/sec} = \text{Bandwidth} / \text{Model Size}$, verified by real benchmarks, shows a strong linear relationship with an R² of 0.9875.
The theoretical background of the Decode stage in LLM inference being bottlenecked by memory bandwidth, along with various real-world benchmark results, clearly demonstrates the performance enhancement potential of CUDIMM. When combined with MoE architecture, CPU offloading efficiency is maximized, allowing large models to run efficiently even with limited VRAM.
Although it is 6.3 times slower than the RTX 4090’s GDDR6X (1,008GB/s), CUDIMM provides practical AI performance without a dedicated GPU. It is a cost-effective and power-efficient solution, especially for mini PCs, ultrabooks, and home workstations.
As CUDIMM technology matures and platform support expands, on-device AI will no longer be the exclusive domain of high-performance GPUs but will become accessible to all users.
References
- https://www.adata.com/us/quikTips/trend-ddr5-memory-comprehensive-analysis-udimm-rdimm-cudimm/
- https://www.corsair.com/us/en/explorer/diy-builder/memory/understanding-corsair-cudimms-a-technical-deep-dive/
- https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
- https://www.jinghong-chen.net/estimate-vram-usage-in-llm-inference/
- https://dev.to/maximsaplin/ddr5-speed-and-llm-inference-3cdn
- https://www.reddit.com/r/LocalLLaMA/comments/1edryd2/how_fast_big_llms_can_work_on_consumer_cpu_and/
- https://www.reddit.com/r/LocalLLaMA/comments/1k4ea74/cpuonly_benchmarks_am5ddr5/
- https://github.com/dmatora/LLM-inference-speed-benchmarks
- https://github.com/vllm-project/vllm/issues/7379
- https://github.com/ggerganov/llama.cpp/discussions/3847